- Topic1/3
34k Popularity
12k Popularity
18k Popularity
7k Popularity
16k Popularity
- Pin
- 🎉 Gate Square Growth Points Summer Lucky Draw Round 1️⃣ 2️⃣ Is Live!
🎁 Prize pool over $10,000! Win Huawei Mate Tri-fold Phone, F1 Red Bull Racing Car Model, exclusive Gate merch, popular tokens & more!
Try your luck now 👉 https://www.gate.com/activities/pointprize?now_period=12
How to earn Growth Points fast?
1️⃣ Go to [Square], tap the icon next to your avatar to enter [Community Center]
2️⃣ Complete daily tasks like posting, commenting, liking, and chatting to earn points
100% chance to win — prizes guaranteed! Come and draw now!
Event ends: August 9, 16:00 UTC
More details: https://www
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974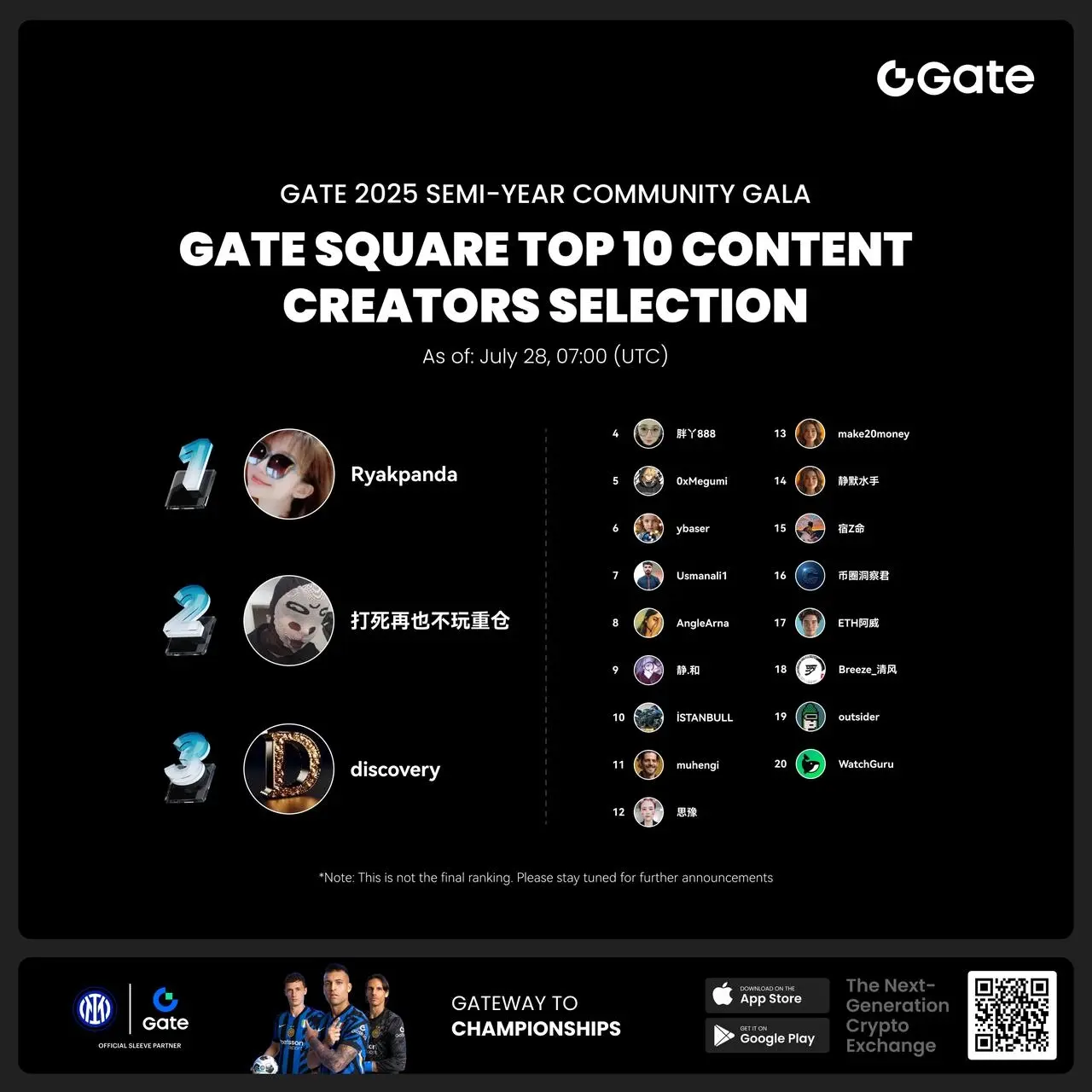
AI and DePIN Integration: Decentralized GPU Networks Leading a New Trend in Computing Power
The Intersection of AI and DePIN: The Rise of Decentralized GPU Networks
Since 2023, AI and DePIN have become popular trends in the Web3 space, with market capitalizations reaching $30 billion and $23 billion respectively. This article will explore the intersection of the two and study the development of protocols in this field.
In the AI technology stack, the DePIN network provides practicality for AI through computing resources. The development of large technology companies has led to a shortage of GPUs, making it difficult for other developers to obtain enough GPUs for computation. DePIN offers a more flexible and cost-effective alternative by using token rewards to incentivize resource contributions that align with the network's goals.
AI DePIN crowdsources GPU resources from individual owners to data centers, forming a unified supply for users who need access to hardware. This not only provides developers with customization and on-demand access but also offers GPU owners additional income.
Overview of AI DePIN Network
Render
Render is a pioneer in providing GPU computing power in a P2P network, focusing on rendering graphics for content creation, and later expanding to include computational tasks ranging from neural radiance fields to generative AI.
Highlights:
Akash
Akash is positioned as a "super cloud" alternative that supports storage, GPU, and CPU computing. Utilizing a container platform and Kubernetes-managed computing nodes, software can be seamlessly deployed across environments to run any cloud-native application.
Highlights:
io.net
io.net provides access to distributed GPU cloud clusters, specifically for AI and ML use cases. It aggregates GPU resources from data centers, crypto miners, and other Decentralization networks.
Highlights:
Gensyn
Gensyn provides GPU computing power focused on machine learning and deep learning computations. It claims to have achieved a more efficient verification mechanism through concepts such as proof-of-learning, graph-based precise positioning protocols, and incentive games involving staking and slashing for compute providers.
Highlights:
Aethir
Aethir is specifically equipped with enterprise GPUs and focuses on computationally intensive fields, mainly AI, machine learning, cloud gaming, etc. The containers in its network act as virtual endpoints for executing cloud-based applications, transferring workloads from local devices to containers for a low-latency experience.
Highlights:
Phala Network
Phala Network serves as the execution layer for Web3 AI solutions. Its blockchain is a trustless cloud computing solution designed to address privacy issues through the use of Trusted Execution Environment ( TEE ).
Highlights:
Project Comparison
| | Render | Akash | io.net | Gensyn | Aethir | Phala | |--------|-------------|------------------|---------------------|---------|---------------|----------| | Hardware | GPU & CPU | GPU & CPU | GPU & CPU | GPU | GPU | CPU | | Business Focus | Graphic Rendering and AI | Cloud Computing, Rendering and AI | AI | AI | Artificial Intelligence, Cloud Gaming and Telecommunications | On-Chain AI Execution | | AI Task Type | Inference | Both | Both | Training | Training | Execution | | Work Pricing | Performance-Based Pricing | Reverse Auction | Market Pricing | Market Pricing | Bidding System | Equity Calculation | | Blockchain | Solana | Cosmos | Solana | Gensyn | Arbitrum | Polkadot | | Data Privacy | Encryption&Hashing | mTLS Authentication | Data Encryption | Secure Mapping | Encryption | TEE | | Work Fees | 0.5-5% per job | 20% USDC, 4% AKT | 2% USDC, 0.25% reserve fee | Low fees | 20% per session | Proportional to staked amount | | Security | Rendering Proof | Proof of Stake | Proof of Computation | Proof of Stake | Rendering Capability Proof | Inherited from Relay Chain | | Completion Proof | - | - | Time Lock Proof | Learning Proof | Rendering Work Proof | TEE Proof | | Quality Assurance | Dispute | - | - | Verifier and Whistleblower | Checker Node | Remote Proof | | GPU Cluster | No | Yes | Yes | Yes | Yes | No |
Importance
Availability of cluster and parallel computing
The distributed computing framework has implemented a GPU cluster, providing more efficient training while enhancing scalability. Training complex AI models requires powerful computing capabilities, often relying on distributed computing to meet demands. For example, OpenAI's GPT-4 model has over 1.8 trillion parameters and was trained over 3-4 months using approximately 25,000 Nvidia A100 GPUs across 128 clusters.
Most of the key projects have now integrated clusters for parallel computing. io.net collaborates with other projects to incorporate more GPUs into its network and has deployed over 3,800 clusters in the first quarter of 2024. Although Render does not support clusters, its operation is similar, breaking a single frame down into multiple nodes for simultaneous processing. Phala currently only supports CPUs but allows CPU workers to be clustered.
Data Privacy
Developing AI models requires the use of large datasets, which may contain sensitive information. Therefore, it is crucial to take adequate security measures to protect data privacy.
Most projects use some form of data encryption to protect data privacy. Render uses encryption and hashing when publishing rendering results, io.net and Gensyn adopt data encryption, and Akash uses mTLS authentication.
io.net has recently partnered with Mind Network to launch fully homomorphic encryption (FHE), allowing encrypted data to be processed without the need for prior decryption. Phala Network has introduced a Trusted Execution Environment (TEE), which prevents external processes from accessing or modifying data through isolation mechanisms.
Proof of Calculation Completion and Quality Inspection
Due to the wide range of services, from rendering graphics to AI computation, the final quality may not necessarily meet user standards. Completing proofs and quality checks is beneficial for users.
Gensyn and Aethir generate proofs after the computation is completed, and the proof from io.net indicates that the rented GPU performance is fully utilized. Both Gensyn and Aethir conduct quality checks on the completed computations. Render suggests using a dispute resolution process; if the review committee finds issues with the node, the node will be penalized. After Phala is completed, a TEE proof will be generated to ensure that the AI agent performs the required operations on the chain.
Hardware Statistics
| | Render | Akash | io.net | Gensyn | Aethir | Phala | |-------------|--------|-------|--------|------------|------------|--------| | Number of GPUs | 5600 | 384 | 38177 | - | 40000+ | - | | Number of CPUs | 114 | 14672 | 5433 | - | - | 30000+ | | H100/A100 Quantity | - | 157 | 2330 | - | 2000+ | - | | H100 Cost/Hour | - | $1.46 | $1.19 | - | - | - | | A100 Cost/Hour | - | $1.37 | $1.50 | $0.55 ( Expected ) | $0.33 ( Expected ) | - |
Requirements for High-Performance GPUs
AI model training requires the best-performing GPUs, such as Nvidia's A100 and H100. The inference performance of the H100 is 4 times faster than the A100, making it the preferred GPU, especially for large companies that are training their own LLM.
Decentralization GPU market providers must compete with their Web2 counterparts not only by offering lower prices but also by meeting the actual needs of the market. Considering the difficulty of acquiring equivalent hardware, the number of hardware that these projects can bring to the network at a low cost is crucial for scaling services.
Akash only has a total of more than 150 H100 and A100 units, while io.net and Aethir have each obtained more than 2000 units. Typically, pre-training an LLM or generative model from scratch requires at least 248 to more than 2000 GPUs in the cluster, so the latter two projects are more suitable for large model computations.
Currently, the cost of these decentralized GPU services on the market is much lower than that of centralized GPU services. Both Gensyn and Aethir claim to offer hardware equivalent to A100 for rent at less than $1 per hour, but this still needs to be proven over time.
The GPU cluster connected via the network has a large number of GPUs with a low cost per hour, but their memory is limited compared to GPUs connected via NVLink. NVLink supports direct communication between multiple GPUs without the need to transfer data between the CPU and GPU, achieving high bandwidth and low latency.
Nevertheless, for users with dynamic workload requirements or the need for flexibility and the ability to distribute workloads across multiple nodes, a decentralized GPU network can still provide powerful computing capacity and scalability for distributed computing tasks.
Provide consumer-grade GPU/CPU
Although GPUs are the primary processing units required for rendering and computation, CPUs also play an important role in training AI models. Consumer-grade GPUs can also be used for less intensive tasks, such as fine-tuning pre-trained models or training smaller models on smaller datasets.
Considering that over 85% of consumer GPU resources are idle, projects like Render, Akash, and io.net can also serve this part of the market. Providing these options allows them to develop their own market niche, focusing on large-scale intensive computing, more general small-scale rendering, or a mix of both.
Conclusion
The AI DePIN field is still relatively new and faces its own challenges. However, the number of tasks performed and hardware in these decentralized GPU networks is still significantly increasing. This trend demonstrates the product-market fit of AI DePIN networks, as they effectively address challenges in both demand and supply.
Looking ahead, the development trajectory of artificial intelligence points to a booming market worth trillions of dollars. These decentralized GPU networks will provide economic benefits to developers.